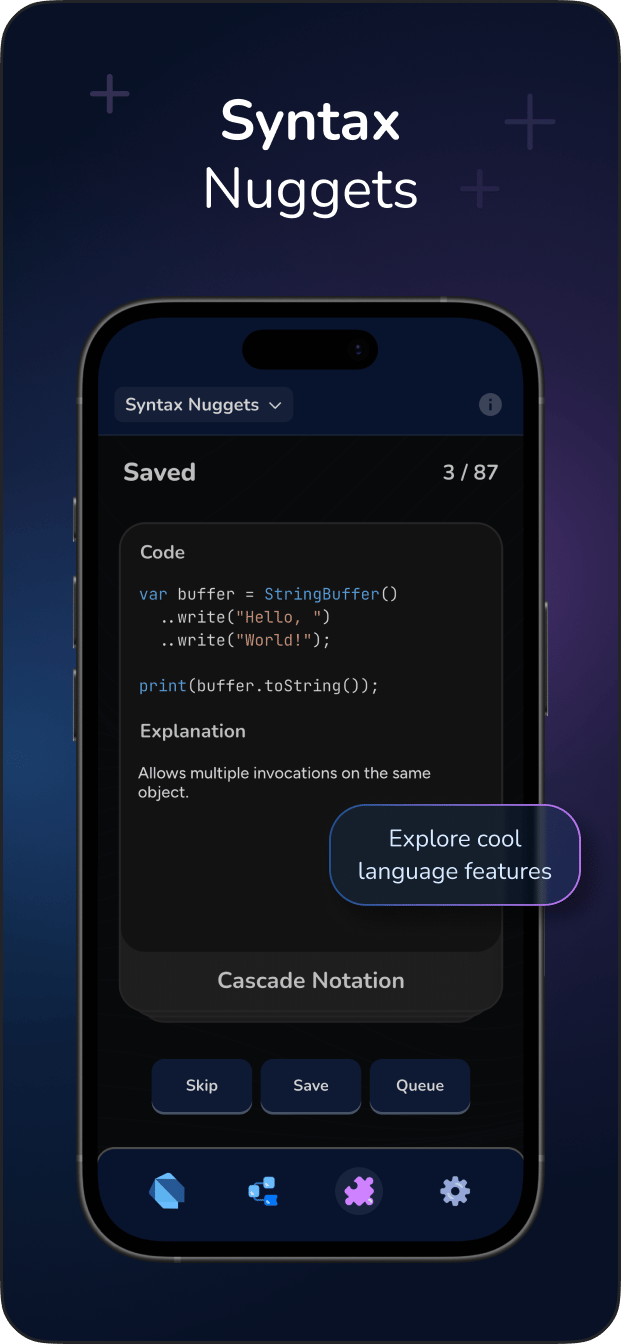
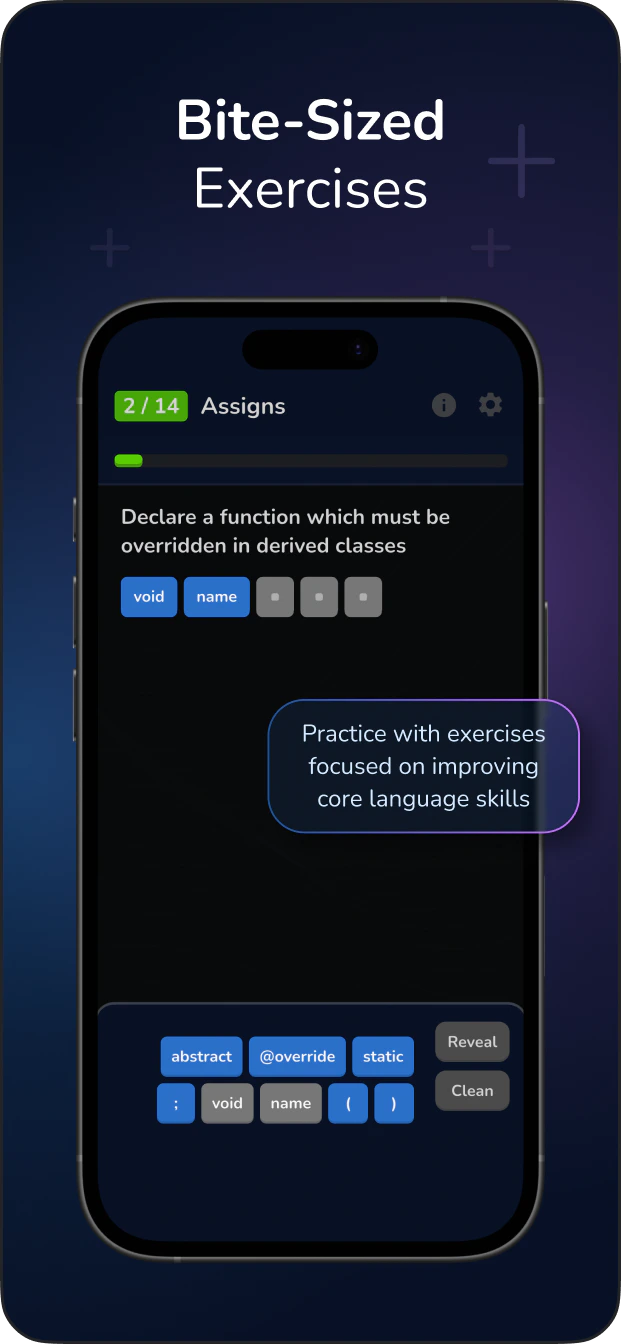
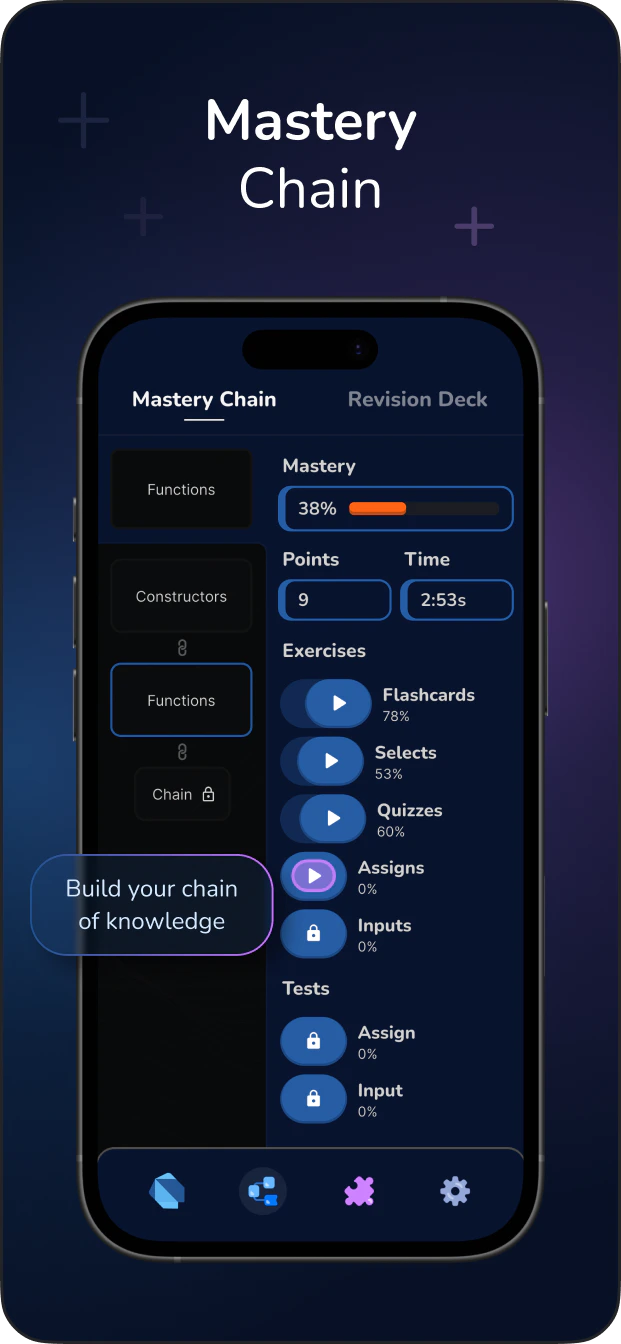
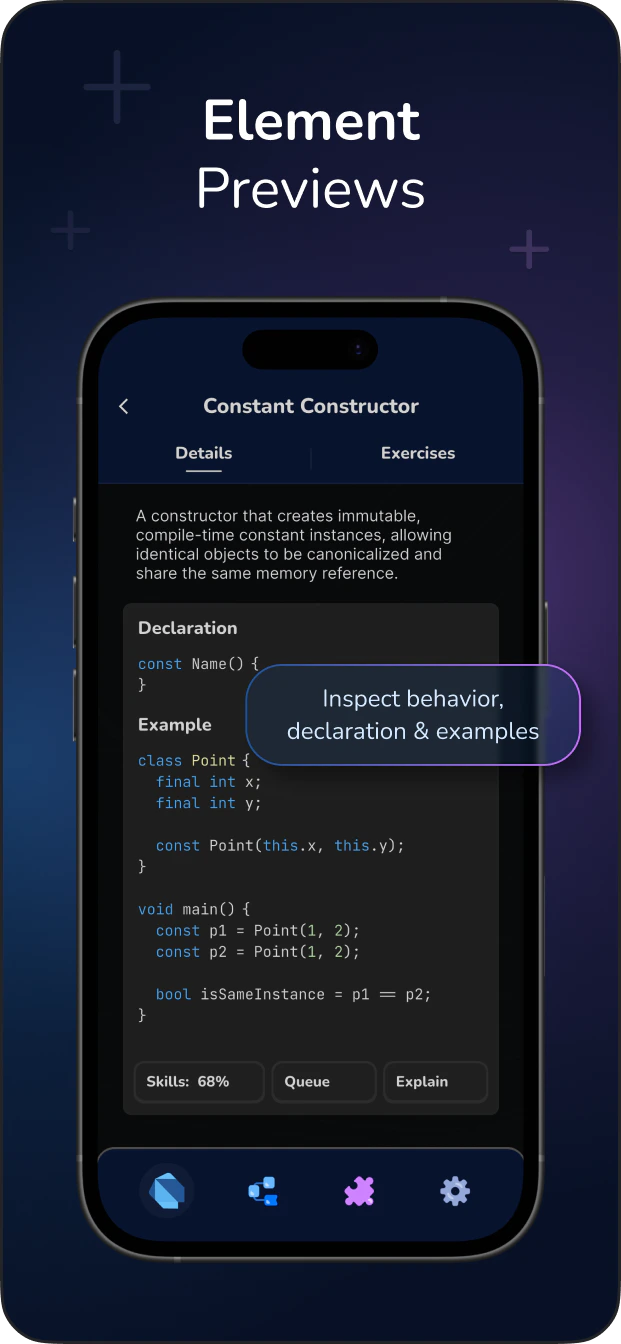
str type is an immutable, ordered sequence of Unicode code points. It is the built-in text sequence type in Python 3, representing text data as a collection of characters where each character maps to a specific Unicode symbol.
Instantiation and Syntax
Strings are instantiated using string literals or thestr() constructor. Python supports multiple literal delimiters to accommodate embedded quotes and multi-line text.
forF(f-strings): Enables literal string interpolation, evaluating expressions inside{}at runtime.rorR(Raw strings): Disables escape character processing (e.g.,\nis treated as a literal backslash followed by ‘n’).uorU(Unicode): Legacy prefix from Python 2; in Python 3, all strings are Unicode by default.
Memory and Internals
Becausestr is immutable, any operation that alters a string allocates a new string object in memory.
Under CPython, the str type utilizes a flexible internal representation (introduced in PEP 393). To optimize memory, CPython dynamically selects the most compact internal encoding based on the largest Unicode code point present in the string:
- 1 byte per character (Latin-1): If all code points are
<= U+00FF. - 2 bytes per character (UCS-2): If all code points are
<= U+FFFF. - 4 bytes per character (UCS-4): If any code point is
> U+FFFF.
Sequence Protocol Mechanics
As a sequence type,str implements the Sequence protocol (__getitem__, __len__, __iter__, __contains__, __add__, __mul__). It supports 0-based indexing, negative indexing, extended slicing, concatenation, and repetition.
Core API and Methods
Thestr class provides a comprehensive suite of methods for text manipulation. Because of immutability, all methods that modify text return a new str instance.
Formatting and Interpolation:
Encoding
Thestr type interacts with raw binary data (bytes) via the encode() method. This translates the Unicode code points into a specific byte representation (e.g., UTF-8, ASCII).
Tired of Poor Python Skills? Fix That With Deep Grasping!Learn More